This is a guest post from Cynthia Weber, Professor of International Relations at the University of Sussex. Weber is the author of Queer International Relations: Sovereignty, Sexuality and the Will to Knowledge which has been the subject of a symposium on this blog, besides also being an occasional contributor to the blog. This text is based on comments presented at the 2017 European International Studies Association Annual Conference, Barcelona, on the panel ‘The Politics and Responsibility of IR in an Age of Crisis’.
A Stanford University study by Yilun Wang and Michal Kosinski that recently went viral repackages long discredited beliefs that a person’s face is scientifically readable for specific personality traits (also see this). The study claims artificial intelligence (AI) facial recognition technology can determine a person’s sexual orientation, with 16-30% greater accuracy than the human eye. The study analyzed more than 35,000 images on a US dating website of white, able-bodied, 18-40 year olds for ‘fixed’ (e.g., nose shape) and ‘transient’ facial features (e.g., grooming styles, weight, facial expressions). Researchers compared their AI-generated sexual orientations against sexual orientations researchers found from dating profiles, which researchers established ‘based on the gender of the partners that [website users] were looking for’.
LGBTQ advocacy organizations immediately labeled the study ‘junk science’. Social scientists will have little trouble understanding why. For example, the study’s sample is skewed in terms of race, age, (dis)ability, and location (online and in the US). Furthermore, the study’s coders failed to independently verify crucial information like age and the problematic category sexual orientation, which are things people regularly lie about on dating sites.
What may be less obvious to many reading the study are some of the other ways biases are created via coding errors or are written into the facial recognition algorithm. For example, the study restricts the range of sexual orientations, sexes and genders to neat yet inaccurate binaries: gay and straight, male and female, masculine and feminine. The study also mistakenly equates sexual orientation with sexual activity, even though people who have same-sex sex do not necessarily identify as gay, lesbian, bisexual or queer. And the study treats ‘transient’ facial features as if they are natural or ‘native’ to ‘gay culture’ and ‘straight culture’, rather than understanding them as performative acts that are highly dependent upon context. In addition to naturalizing culture, this move overdetermines how ‘gay’ and ‘straight’ are coded. For it fails to recognize that people who choose to go on a dating site will likely post photos of themselves that can be easily understood through sexualized stereotypes, which they may or may not perform in other on- and off-line contexts.
If there are so many problems with this study, why should any of us give it a second thought, particularly (IR) scholars, policymakers and activists? And why should this study be the focus of reflections on the politics and responsibility of International Relations in an age of crisis?
I have five answers.
Answer One: History
While the Stanford study is a new study, it does not mark the emergence of a new problem or a new crisis, either for those who are included in the study as ‘straight’, ‘gay’ or ‘lesbian’, or for those who are excluded from it. Rather, the Stanford study is but a recent example of how coherence is imposed upon people in various places and at various times to produce them as knowable subjects. For example, ‘the homosexual’ and ‘the heterosexual’ are historical inventions that the Stanford study both takes as ‘natural facts’ and further coheres into ‘natural facts’. It does this by repackaging the discredited pseudo-science of physiognomy into the increasingly credible (pseudo-)science of AI deep facial recognition and then linking AI-generated sexual orientation with biologically determinate understandings of sexual orientation. What the AI facial recognition algorithm tells us, according to Wang and Kosinski, is that, ‘Consistent with the prenatal hormone theory of sexual orientation, gay men and women tended to have gender-atypical facial morphology, expression, and grooming styles’.
Answer 2: Knowledge
Knowledge claims like Wang and Kosinski’s are often made about what and who it is most difficult to know for sure. A desire to know for sure can lead investigators to attribute scientific certainty to scientifically uncertain categories, conclusions, and investigative techniques. Wang and Kosinski make all of these errors. Not only are their claims about the problematic category sexual orientation and its attribution to people with presumably different kinds of faces scientifically dubious. Their claim that AI facial recognition technology ‘knows’ one’s sexual orientation better than the human eye assumes that an AI posthuman superintelligence that actually, accurately and objectively ‘machine-learns’ and ‘machine-knows’ sexual orientations exists in a usable, scientifically reliable (enough) form. It doesn’t, according to the FBI, US National Institute for Standards and Technology, and the US Department of Defense.
Substituting a will to knowledge about a person’s sexuality or sexual orientation with scientifically (and otherwise) uncertain categories, conclusions and investigative techniques is nothing new. It is such a staple of modern Western science in studies of gender non-conforming, sexually minoritized, and otherwise minoritized people that it cannot be disentangled from the scientific methods of these studies themselves.
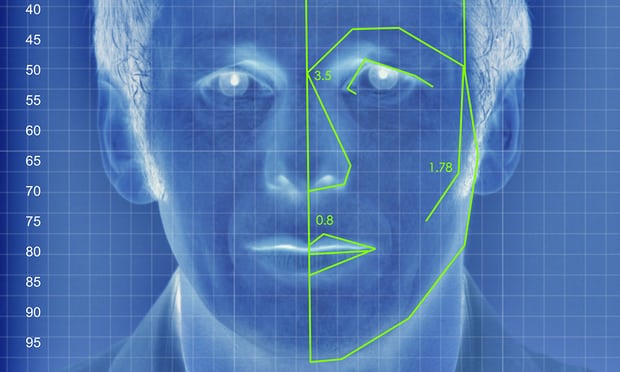
An illustrated depiction of facial analysis technology similar to that used in the experiment (illustration: Alamy; source: Guardian)
Answer 3: Imaginaries
When dubious scientific techniques and the knowledge claims they produce are supported by social and cultural prejudices, they tend to gain credibility and lodge themselves more deeply into wider fields of understanding – from science to medicine to law to social policy. The Stanford study illustrates this long-standing trend.
In general terms, the presumed coherence of ‘gays’ and ‘straights’ is made possible because it is supported by modern social imaginaries. Our willingness to accept that there are such things as coherent sexes, genders, and sexual orientations stems not only from our imaginaries about sex, gender and sexuality but also from our imaginary about the possibility and existence of coherent identities. Our willingness to exclude people of color, people with disabilities, people of a certain age, people located off-line or out of the US are as tied up with imaginaries around race, ability, age, and location as they are with Western colonial and imperial imaginaries and the material politics that sustain them. Our willingness to believe that an AI facial recognition algorithm actually, neutrally and better distinguishes ‘gay people’ from ‘straight people’ accords with Western imaginaries about scientific knowledge and technological progress.
Answer 4: Values
Not only do we value these imaginaries. We use these imaginaries to assign values to particular people and particular populations. And that’s easy to do because the imaginaries themselves already map the world in terms of who or what is valuable or not. Many scientific imaginaries contain values like these:
- A ‘normal’ coherent subject who can be read and known as a coherent identity is valued over a ‘deviant’ incoherent subject whose identity remains mysterious;
- Scientific knowledge channeled through advanced technology best helps us sort through and order indicators of coherence, normality and deviance;
- Once subjects have been scientifically identified, we can further specify their value or lack thereof.
Junk scientific methods – like those used by the Stanford study – have a long history of operationalizing lived incoherence out of scientific investigations at the outset, thereby skewing results toward finding ‘coherent subjects’. This helps explain how sexual orientation was reduced to the binary ‘gay’ or ‘straight’ and how the Stanford study reaffirmed its pre-determined knowledge about the existence of ‘gay’ and ‘straight’ people. Moves like this one didn’t start with the Stanford study. Perceived sexuality – like perceived race, ability, age, and (national) location – has long informed ‘scientific understandings’ of ‘the normal subject’ and ‘the deviant subject’.
Historically, these understandings have been used to prove and approve Western valuations of ‘heterosexuals’ as normal and ‘homosexuals’ as perverse, which were spread by the British imperial practice of criminalizing same-sex behavior, for example. Even as same-sex coupledom is or was being normalized in some places, this merely evidences how the category of the ‘normal’ coherent sexualized subject can be expanded to include and value some ‘gays’ and ‘lesbians’ while continuing to exclude and devalue others.
Answer 5: Orders
Understandings and valuations of sexualized subjects do not just inform personal biases and personal choices. They participate in the ordering of intimate, familial, national, regional and international politics. In terms of International Politics, we see this in how IR theorists and practitioners have historically entangled knowledge about ‘the heterosexual’ vs. ‘the homosexual’ with theories and policies about development, immigration, security, human rights, and regional and international integration.
Queer International Relations scholars and practitioners demonstrate, for example:
- How the Obama administration’s championing of ‘gay rights as human rights’ was grounded in a specific understanding of ‘the LGBT’;
- How the World Bank’s development policies to combat ‘the economic costs of homophobia’ rely upon a specific understanding of ‘the normal’ or ‘normalizable LGBT’; and
- How understandings of ‘the radical Islamic terrorist’ that are as sexualized as they are racialized and religiousized inform many contemporary Western security policies.
There is no reason to believe that the presumed knowledge about ‘gays’ and ‘straights’ generated by AI facial recognition technology will not itself create new opportunities and new dangers for ‘coherently knowable’ and ‘incoherently unknowable’ sexualized subjects.
Implications
The Stanford study mentions the implications of AI technology for privacy. That is crucially important. AI facial recognition technology will likely erode individual privacy rights, like the right to keep one’s presumed sexual orientation as private as possible and as fluid as one wants it to be. Yet in the contemporary legal context in which people’s faces are generally considered to be ‘public information’, many other issues arise. This is particularly the case when AI technology becomes entangled with how individuals, states, corporations and international institutions ‘know’ people and map our worlds. For example, might information about one’s sexual orientation begin to appear on all forms of legal identification? Because AI algorithms that claim to determine sexual orientation are admittedly imprecise, might future IDs carry both one’s sexual orientation and an accuracy reading of that sexual orientation? Might that lead to thresholds being developed for services, rights, and risks?
Consider scenarios like these:
- A person is denied access to a religious service because they scored less than a 90% accuracy rate as straight; or
- A person is criminally tagged in a place with laws again homosexuality if they score 50% or above ‘gay’ or ‘lesbian’; or
- A ‘gay male’ has their health insurance premiums raised if their accuracy rating is 60% or above, while a ‘lesbian female’ has their health insurance premiums lowered if they have the same accuracy rate.
If we get to this point, will we be so caught up in calculating our own advantages and disadvantages based on our AI-generated sexual orientation ratings that we lose sight of how the cultural designation ‘sexual orientation’ and its incumbent prejudices have been naturalized? Will we forget that sexual orientation scores of ‘gays’ and ‘straights’ are and always were like other knowledge about ‘gays’ and ‘straights’? They are figurations – social meanings condensed into forms or images through applications like AI machine-learned and machine-known sexual orientations. Will we forget how contestable these figurations are and always were, and how they map the world in contestable ways?
All of this contributes to my understanding of contemporary crises. It makes me wonder how AI-generated sexual orientations might be mobilized by states, corporations and private individuals to generate crises, to explain and apportion blame for crises, to attach themselves to other crises, or to claim to resolve crises.
We get a sense of how this might happen by remembering how these moves have been and are happening. For example, the figures of ‘the perverse homosexual’ and ‘the perverse trans*person’ have been and are being used to generate crises around military service, adoption, marriage, human rights, even bakery services. These figures have been used to explain and apportion blame for crises like the 9/11 terrorist attacks in the US, the Balkan floods after Conchita Wurst won Eurovision, and even Hurricane Harvey that hit Texas last month. These figures have been used to attach specific crises to specific figures, as happened to the figure of ‘the gay man’ in relation to the HIV/AIDS crisis. And refiguring ‘the perverse homosexual’ into ‘the normal LGBT’ was used by the Obama administration to attempt to resolve the human rights crisis for LGBT people, by championing ‘gay rights as human rights’.
These examples span a wide range of crises from state security to public health to climate change. These are crises that are made to be about specific types of sexualized subjects, even though they are not actually about them. There is no reason to believe AI-generated sexual orientations will not be used to support or resolve other crises, national and international.
For example, in various national contexts, might the Stanford study’s normal white subject buttress claims by white ethno-nationalists to the normalcy of white supremacy, a belief structure that is not only racialized but also sexualized? Also, at this moment when the Trump administration decided not to include sexual orientation and gender identity in the US Census, could specialized US government AI algorithms end up being used to generate sexual orientations to replace self-understandings and self-reporting by US citizens? Who would write these algorithms, for what ends, and how might they be replicated and/or modified in other locales?
In national and international contexts, might the Stanford study be used to resolve Western dilemmas around migration, which sees Western states close their borders to most migrants while accepting those people they label ‘genuine asylum seekers’? Might AI-generated sexual orientations be used to determine who is and is not a genuine asylum seeker on the basis of sexual orientation? Might this be just one way that AI-generated sexual orientations could become part of what that Didier Bigo calls Global Preventive Security? Might their use recode ‘the digital accident’ into ‘superintelligent knowledge’, creating even more risks and insecurities for asylum seekers? And – in any or all of these national and international examples – what prevents AI from learning to be homo/bi/trans* phobic, as in another case it learned to be racist, sexist, and misogynist?
Conclusion
As flashy headlines about the promises and risks of AI in general and AI-generated sexual orientations in particular grab our attention, we must not be distracted from fundamental issues that get pushed aside about both presumed sexual orientations and about AI, like:
- Presumed sexual orientations – be they human-read or machine-read – arose from and continue to legitimate histories, knowledges, values, imaginaries, and orders that very often put especially queers, gender variant, non-gender conforming and other non-normalized people at risk (e.g., people of color and people with disabilities).
- Neither governments nor corporations have a right to ‘learn’ and ‘know’ anyone’s presumed sexual orientation, even though they increasingly claim this right without consent.
- AI algorithms don’t actually ‘learn’ or ‘know’ the way humans learn and know. While humans write AI algorithms and input binary codes and human biases into these codes, even these programmers do not understand the parameters AI ‘deep learning’ algorithms use to make decisions. This is true even of simple determinations like, ‘Who will be the best employee?’ We have no idea what this might mean in the determination of one’s presumed sexual orientation and how that might be related to all manner of AI decision-making.
- Like ‘robots [that] work best when the world has been arranged the way they need it to be arranged in order to be effective’, AI algorithms might reorganize our worlds into increasingly closed systems, in which they function more easily than in the messy open-ended domains in which we actually live. And because AI is taking hold of our worlds through a ‘slow creep’, we may notice this only after it has occurred. This might not just affirm outdated binary understandings of sex, gender and sexuality; it might (re)produce a world in which these binaries are scientifically revalidated, further endangering especially those people who are ‘unreadable’ and thus ‘unknowable’ in binary terms.
These issues don’t just arise in the widely discredited Stanford study. They are part and parcel of long traditions of bad science on sexuality and race as well as the emerging technologies of artificial intelligence and the specific algorithmic imaginaries they rely upon and fuel. What makes the Stanford study worth our attention are two things. One is how it combines the worst of all of these elements into another suspect tool governments and corporations could use to regulate people in terms of their presumed sexuality, in ways none of us either choose or fully understand. This is a potential crisis-in-the-making. Another is how it reminds us that as governments and international organizations delve further into AI research and its applications, the risks of their making similar mistakes that compound this potential crisis multiplies.
We have a political responsibility to monitor, critically interrogate, and influence how AI is used to imagine and combine (pseudo-)science and technology with things like sexuality, gender, race, age, ability and class. What is at stake is much more than a badly designed academic study. It is (potential) AI applications by individuals, corporations, nations, and international organizations that could be better, as bad as, or even worse than those of the Stanford study.

Reblogged this on sexuality and space.
LikeLike
Pingback: Tell me what you see and I’ll tell you if you’re gay: Analysing the Advocate General’s Opinion in Case C-473/16, F v Bevándorlási és Állampolgársági Hivatal – LaPSe of Reason
Pingback: Analysing the Advocate General’s Opinion in Case C-473/16, F v Bevándorlási és Állampolgársági Hivatal – Good Legal Advice
Pingback: Analysing the Advocate General’s Opinion in Case C-473/16, F v Bevándorlási és Állampolgársági Hivatal – somerset Solicitors
Pingback: EU Law Analysis: Tell me what you see and I’ll tell you if you’re gay: Analysing the Advocate General’s Opinion in Case C-473/16, F v Bevándorlási és Állampolgársági Hivatal
Pingback: How Should UN Agencies Respond to AI and Big Data? | The Global
Pingback: AI & Global Governance Platform: How Should UN Agencies Respond to AI and Big Data? - United Nations University Centre for Policy Research
Pingback: Analysing the Advocate General’s Opinion in Case C-473/16, F v Bevándorlási és Állampolgársági Hivatal – EU Immigration and Asylum Law and Policy – Audreysalutes.com